목차
Today I Learned
- 검색을 이해하려면 다양한 DB를 알아야 돼! - DataBase
- 검색 결과를 페이지네이션과 연결해야 돼! - Search / Pagination
- 검색하기 버튼 없이 검색을 한다고?! - Debouncing / Throttling
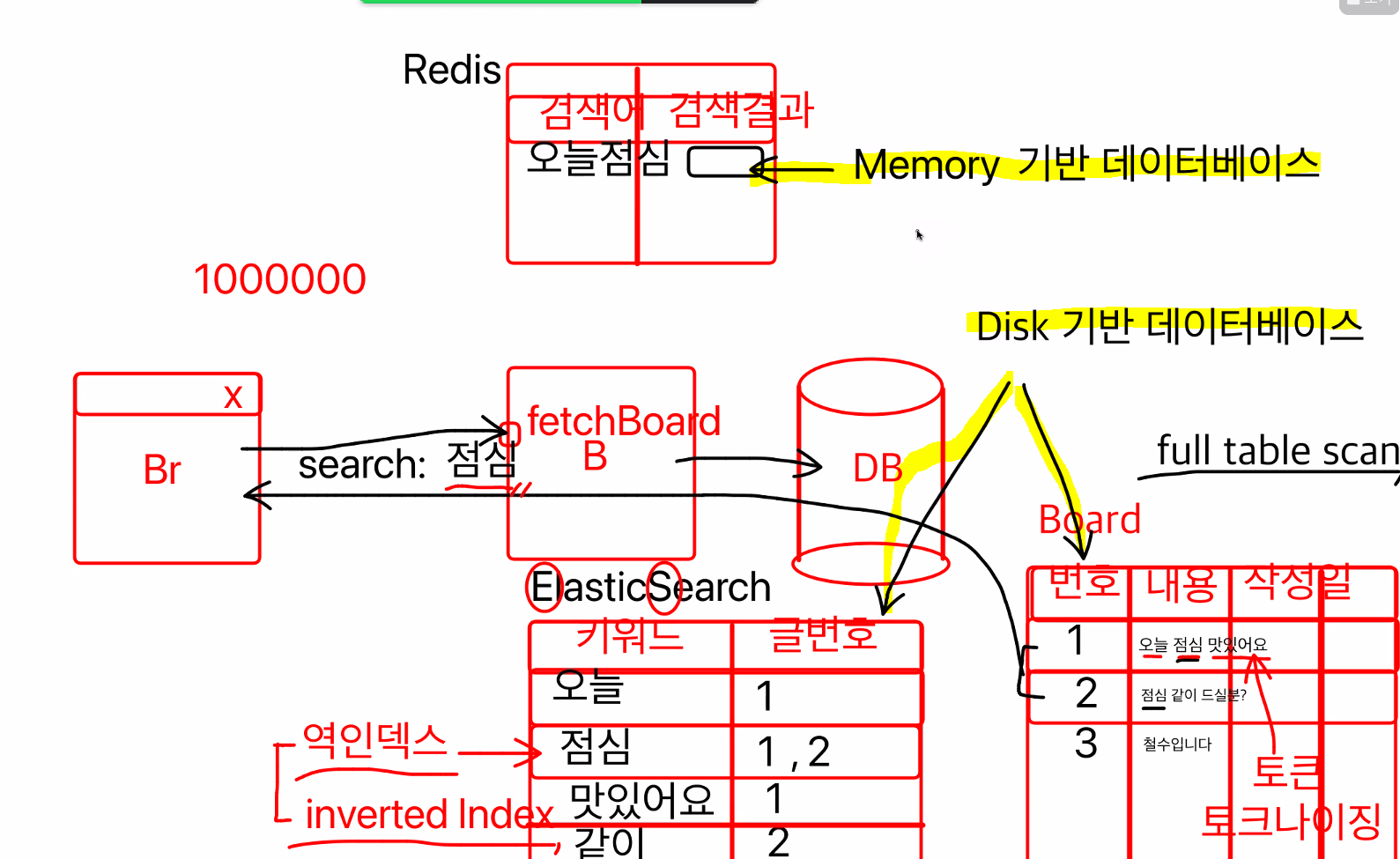
검색 프로세스 이해 (ES, Redis 등)
백엔드의 검색 시스템 구조에는
가장 기본적으로테이블을 풀 스캔하는 방식(full table scan)으로
전체 테이블 로우를 조회하는 방법이 있습니다.
초기에 빠르게 만들기 위한 방법으로 사용되고,
서비스 규모가 커짐에 따라 이러한 방식은 잘 사용되지 않습니다...
웹서비스의 검색 의 가장 기본적인 프로세스는 다음과 같습니다.

Browser에서 검색 요청을 하면
Back-end에서 DB 내부의 수 많은
Data들 속에서 요청받은 keyword를 가지고
full table scan 말 그대로 테이블 전체를 싹 다 조회합니다.
Data가 많을 수록 속도가 느려져서 성능이 썩 좋지는 못합니다.
처음 간단히 만들어 볼때 사용하는 방식이고
실제 서비스하기에 좋은 방식은 아닙니다.
이런 방식의 단점을 보완하는 방식도 있는데요?
역인덱스 (inverted Index)
바로 문장들을 단어 하나하나로 쪼개는 것입니다!
쪼개진 단어 하나하나를 토큰(분리된 문자열 조각)이라고 하고
이렇게 문자열을 분리하는 것을 토크나이징이라고 합니다.
원래 인덱스(글번호) 기준으로 조회하던 방식에서
토큰 키워드 당 인덱스(글번호)들을 모아오는 식으로
인덱스를 역으로 돌렸다고 하여 이런 방식을 역인덱스 라고 합니다.
이렇게 Data를 특정 키워드들로 구분지어 해당하는 글들을 모아
역인덱스 방식(Inverted Index)으로 저장되게 된다면
특정 키워드에 대한 글들의 검색이 빨라집니다.
ES (Elastic Search) - Disk(비휘발성/비소멸성) 기반 DB
이런 방식을 쉽게 만들어 주는 도구인 데이터 베이스 Elastic Search 가 있습니다.
이 방식은 Disk에 저장되는 방식으로 컴퓨터가 꺼져도 저장이 유지(비휘발성)됩니다.
분명 안전하지만 속도는 조금 떨어지게 됩니다.
Redis - Memory(휘발성,임시저장) 기반 DB
트래픽이 많아지면(=접속자가 많아지면)
중복이 되는 검색어 키워드들이 어느정도 모아집니다.
(그런 검색어들이 검색어 검색 결과로 뜨게 됩니다.)
그런 중복되는 키워드들 만 저장하는 공간이 Redis 입니다.
Memory는 임시저장방식(휘발성)으로 Disk저장보다는
안정성이 떨어지지만 속도가 빠릅니다.
이러한 메모리저장기반 방식이 Redis입니다.
왜 Disk 놔두고 Redis를 쓸까요?
Disk는 컴퓨터 껐다 켜도 데이터가 살아있고
Memory는 껐다 켜면 날아가죠.
저장 된게 안날아가니까 Disk가 더 좋습니다.
그럼 굳이 Memory 왜 쓸까요?
디스크는 안전하게 저장하다 보니 속도가 느립니다.
검색 키워드마다 디스크까지 가서
데이터를 꺼내오면 속도가 느리겠지요.
메모리는 속도가 굉장히 빠릅니다. 한두배 정도가 아니라 훨씬 빠릅니다.
그래서 Elastic Search 가 빠릅니다.
사람들이 자주 검색하게 되는 것들은 검색마다
Disk에 가서 꺼내오는것보다는 Memory 기반 DB에 넣어두면
그때 그때 마다 더 빠르게 제공할 수 있게 되는 것입니다.
검색 로그를 패싱해놓고 자주 검색되는 목록인 Redis로 갔는데
거기에 해당 data가 없으면 그 때 가서
Elastic Search에서 data를 찾는 식으로 하여
퍼포먼스를 향상시킬 수 있습니다.
이런 방식을 검색로그 캐싱 이라고 합니다.
즉, 검색이 진행될 때, 캐싱이 되어있다면 Redis ,
캐싱되어 있지 않은 기록은 Elastic Search 방식 이 사용되는 것입니다.
디바운싱 & 쓰로틀링
디바운싱 - 처음 함수 처리 (검색기능)
디바운싱이란, 연이어 발생한 이벤트를 하나의 그룹으로 묶어 처리하는 방식으로
주로 그룹에서 마지막, 혹은 처음에 처리된 함수를 처리하는 방식으로 사용됩니다.
마지막 호출이 발생한 후 일정 시간이 지날때까지 추가적 입력이 없을때 실행이 됩니다.
디바운싱이 사용되는 대표적 예제로는 검색기능이 있습니다.
쓰로틀링 - 나중 함수 처리 (스크롤 기능)
반면 쓰로틀링이란, 연이어 발생한 이벤트에 대해 일정한 delay를 포함 시켜, 연속적으로 발생하는 이벤트는 무시하는 방식으로 사용됩니다.
즉, 지정한 delay동안 호출된 함수는 무시합니다.
쓰로틀링이 사용되는 대표적 예제는 스크롤 기능이 있습니다.
Lodash 디바운싱 구현
Lodash는 자바스크립트의 유틸리티 라이브러리입니다.
내장되어 있는 유용한 함수가 많기 때문에 자주사용 됩니다.
Lodash의 많은 기능 중 디바운싱이 있습니다.
npm에서 검색하여
아래 명령어로 설치해줍니다.
yarn add lodash
yarn add -D @types/lodash
Debounce 활용하는 곳
디바운스는 검색에 활용할 수 있습니다.
우리가 검색을 할 때 엔터를 치지 않더라도,
사용자가 입력을 멈추고 일정 시간이 지나면
자동으로 함수를 실행시켜 검색 결과를 보여주는 것입니다.
그러면 아주 편리하겠네요!
오늘의 정리
풀 테이블 스캔의 단점을 보완하는 방식으로써 데이터베이스에 저장할 때, 문장을 키워드 단위로 토크나이징(컴퓨터에게 이해 시키기 위해 우리의 언어를 의미가 있는 가장 작은 단어로 나누는 것)하고, 역인덱스(inverted index)를 만들어서 저장했습니다. 이를 쉽게 해주는 데이터베이스 프로그램이 엘라스틱서치(ES)였죠!
마지막으로, 서비스가 더 커지게 되면, 수많은 사람들이 검색하는 데이터는 어느정도의 틀에서 크게 벗어나지 않는다 했습니다! 따라서, 검색어와 매칭되는 검색결과를 메모리에 저장(검색로그 캐싱) 후, 빠르게 찾아쓸 수 있도록 도와주는 데이터베이스 프로그램이 존재하는데 이것이 **레디스(redis)**입니다!
위 두 데이터베이스의 가장 큰 차이는 저장 방식이였습니다! redis는 휘발성 데이터 저장방식 memory기반, 엘라스틱서치는 하드에 저장시켜 데이터가 보존되는 disk기반이였죠!? 두 방식 모두 장단점이 존재했습니다! 상황에 따른 활용으로 성능을 더욱 효율적으로 끌어올릴 수 있다는걸 기억하셔야 합니다!
프론트엔드에서 검색 기능을 수행하기 위해 api 요청 시 검색 키워드를 함께 넘겨주었죠!? 여기서 핵심은 검색 결과와 페이지네이션과의 관계였습니다! 검색어를 기준으로 페이지네이션이 새롭게 만들어져야했죠? 따라서 우리는 검색어를 기준으로 refetch를 실행해주었습니다! 여기서 문제가 있었죠!? 검색어를 변경하고 검색을 누르지 않았는데 페이지를 이동했을때, 검색어가 변경된다는 점 이였습니다! 이를 해결하기 위해 state를 search와 keyword로 나누어 주었습니다!!
마지막으로 검색 버튼 없이 검색하는 방법에 대해서 배웠는데 여기서도 문제가 하나 있었습니다! 검색어를 하나 입력할 때 마다 gql요청이 연속적으로 보내졌죠? 이렇게 되면 백엔드 컴퓨터의 메모리,cpu 낭비가 심해져 효율이 떨어진다 했습니다! 이 때, 연속적으로 요청되는 쿼리를 막기 위해서 디바운싱 이라는 기술을 활용했습니다! 디바운싱은 반복적인 요청을 일정한 텀을 가지고 한번에 묶어서 요청해주는 것! 기억나시죠!?
반대로 쓰로틀링도 있었습니다! 쓰로틀링이란 마우스 이동, 스크롤 이동을 감지하면 특정 이벤트를 실행시키고, 이동이 멈출때까지, 이벤트가 재실행 되지 않도록 막기 위해 사용했습니다. 이러한 기술을 쉽게 사용 가능하도록 자주 사용되는 라이브러리가 바로 lodash 였습니다!
마지막으로 검색어에 해당하는 단어의 색을 변경했습니다! replaceAll을 통해 검색어 키워드 앞,뒤에 시크릿 코드를 붙여 split을 사용해 잘라낸 후 map으로 화면에 출력해주었죠!? replaceAll -> split -> map 흐름을 기억하시길 바랍니다!
Reference
- https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=777lover&logNo=220689735431
'리액트 공부와 함께 하는 일상 > 4주차' 카테고리의 다른 글
| [TIL] 4주차 - 7. 검색 (0) | 2022.03.23 |
|---|---|
| [TIL] 4주차 - 5. 이미지 파일 업로드 (0) | 2022.02.08 |
| [TIL] 4주차 - 4. Firebase BAAS 서비스 (0) | 2022.02.07 |
| [TIL] 4주차 - 3. CORS (Cross-Origin Resource Sharing) (0) | 2022.02.07 |
| [TIL] 4주차 - 2. 웹 서비스 구조 / SQL / NoSQL (0) | 2022.02.07 |


댓글